

TL;DR · Key Takeaways
- The VCF 9 hierarchy is Fleet, then Instance, then Domain (management and workload), then vSphere cluster. Learn it in that order.
- A fleet is the shared-services and governance boundary, not a single shared vCenter. VCF Operations and VCF Automation live at the fleet level.
- An instance is a discrete SDDC footprint. A domain is the lifecycle and blast-radius unit.
- A new management domain needs 4 hosts. Converge needs 3 vSAN-ready or 2 with external storage. Import matches that lower floor.
- Schedule change windows at the domain and fleet-services levels, not at the vCenter level.
Most VCF 9 design mistakes I see are not technical, they are vocabulary. Someone draws a fleet on the whiteboard, calls it an instance, then plans change windows as if a vCenter were the unit of isolation. The new hierarchy is genuinely different from VCF 5.x, and getting the four words right (fleet, instance, domain, cluster) is what keeps your design and your maintenance plan honest.
The hierarchy, top to bottom
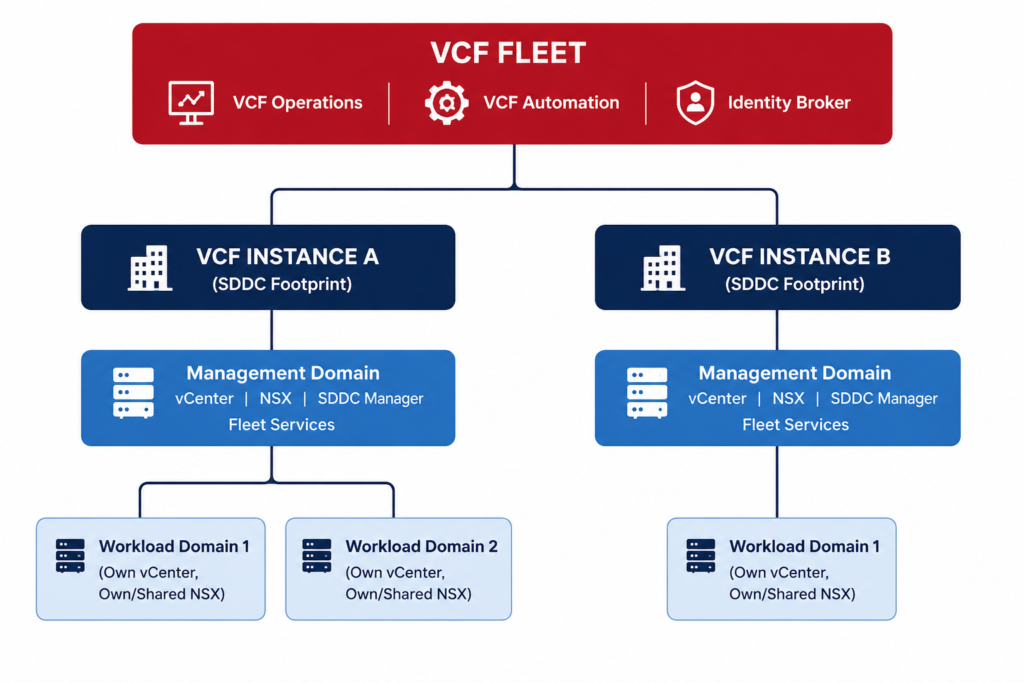
Read it as nesting, not as synonyms. The fleet is the outermost boundary. Inside it sit one or more instances. Each instance contains exactly one management domain and zero or more workload domains. Each domain contains one or more vSphere clusters. Private cloud is the program label on top, but fleet, instance, and domain are what you actually operate.
The fleet is shared services, not a shared vCenter
This is the one people get wrong. A fleet is the scope for the shared, fleet-level components: VCF Operations, VCF Operations fleet management, VCF Automation, and the VCF Identity Broker that backs VCF SSO. It is a governance and shared-services boundary, not a single pane of vCenter. The first instance you deploy hosts those fleet services in its management domain. Add a second instance and it joins the same fleet, consuming the same Operations and Automation rather than running its own. That is the mechanism behind the single-private-cloud experience introduced in Part 1.
Instance versus domain
An instance is a discrete SDDC footprint: its own management domain plus workload domains, each with their own vCenter, NSX, and SDDC Manager. An instance is not a tenant boundary by default. The domain is where isolation actually lives. A workload domain commonly carries its own vCenter, its own vCenter SSO domain, and NSX that you can choose to dedicate or share. The domain is your lifecycle unit and your blast radius. When you reason about what breaks when, reason at the domain level.
That failure model is worth teaching the whole team. A fleet-services outage costs you visibility, governance, automation, and lifecycle workflows. It does not delete vCenters or power off ESX hosts. An instance or management-domain outage costs instance-level lifecycle. A workload-domain outage is the layer that actually touches tenant workloads. Three very different blast radiuses, three different change-control conversations.
Host counts and how instances are born
A new VCF 9 management cluster requires 4 hosts, on vSAN, NFS, or VMFS on FC. The four-host floor exists so a host can enter maintenance mode without breaking vSAN quorum. Two of the brownfield pathways are more forgiving: converging an existing vCenter needs 3 vSAN-ready nodes or 2 hosts on external storage, and importing a vCenter as a workload domain has the same lower minimum. There are four ways to bring an instance into being: deploy a new instance as a new fleet, expand an existing fleet with another instance, converge a non-VCF vCenter into a management cluster, or import a vCenter as a workload domain. We cover choosing between them in the adoption-paths decision guide.
One convergence caveat shapes a lot of designs: an existing vCenter with NSX already installed is not supported for converging to a management domain on 9.0.0, where NSX is freshly deployed during conversion. That single rule pushes many brownfield NSX shops toward the import path instead.
Single fleet or many
A fleet can be one instance or many. The instinct is to build one fleet to rule everything, because shared Operations and Automation are convenient. Resist that instinct when you have regulated business units or hard isolation requirements. A single shared fleet-services layer is a single shared dependency for your entire program’s provisioning and governance. If you need real separation, stand up a second fleet up front. Retrofitting SSO and identity separation after the fact is the genuinely painful design change to unwind, and detailed sizing of the management domain that carries those services is covered in the reference architecture deep-dive.
Identity and SSO are a fleet decision
The fleet boundary is also your identity boundary, and that is the part people underweight at design time. The VCF Identity Broker backs VCF SSO at the fleet level, which means the authentication and authorization story is shared across every instance in the fleet. Workload domains can still carry their own vCenter SSO domain, so there is isolation below the fleet, but the fleet-wide identity plane is a single shared dependency. If two business units need genuinely separate identity, audit, and governance, that is the strongest argument for a second fleet rather than a second instance. Splitting identity after the fact, once provisioning and RBAC are wired through a shared broker, is the design change I least like to do under a deadline.
The 9.0 component set, named
It helps to know exactly what a VCF 9.0 instance is made of, because the names appear throughout the consoles and the release notes. At GA the stack is vCenter, ESX, NSX, SDDC Manager, VCF Operations with its Operations Fleet Management and Operations Collector, VCF Automation, and the VCF Identity Broker, all carrying 9.0.0.0 component versions. The single instances in a management domain are vCenter, SDDC Manager, the Fleet Manager, and the Operations Collector. The components you cluster for HA are NSX Manager, VCF Operations, VCF Automation, and Operations for Logs, each as a three-node set. Keeping that inventory straight is what lets you reason about which failures touch which layer, which is the whole point of learning the hierarchy in the first place.
Why the consolidated label faded
If you came from VCF 5.x you will reach for the consolidated and standard architecture terms. VCF 9 leans on the domain model instead and dropped the consolidated label because it caused confusion. The supported topology is now described two ways: combine management and workload in a single cluster, or separate them into a management domain plus workload domains. The substance is unchanged, a small or constrained environment can still collapse everything into one cluster with resource pools, but the framing moved to the domain. When you write a customer design, describe what the clusters and domains do rather than reaching for the old label, and confirm any terminology against the current design guide so your deliverable matches the console the customer will actually see.
What I’d Do
Whiteboard the fleet, instances, and domains explicitly before you size a single host, and label every change window with the layer it touches. The most expensive mistake is conflating fleet and instance, then scheduling maintenance at the vCenter level, because you end up underestimating both the blast radius and the shared-dependency risk. For regulated tenants, pay the second-fleet tax now. For everyone else, one fleet with cleanly separated workload domains is the pragmatic default. Which layer in your design carries the most shared risk today, and is that on purpose?
References
- VCF Blog: Deployment Pathways for VMware Cloud Foundation 9
- Broadcom TechDocs: Building Your Private Cloud Infrastructure (VCF 9)
- VCF Blog: Planning a Successful VCF 9.0 Deployment






