When people talk about AI, most of the focus is on models—LLMs, vision models, benchmarks, and capabilities. But in real-world systems, the bigger challenge is not just building or choosing a model. It’s how you run that model efficiently at scale.
This is where NVIDIA NIM (NVIDIA Inference Microservices) becomes important.
At a simple level, NIM turns AI models into ready-to-use, optimized services. Instead of worrying about deployment, scaling, and performance tuning, you can directly use models through APIs that are already optimized for your hardware.
The Real Problem with AI in Production
Running AI models in production is not straightforward.
You need to:
- Configure GPUs correctly
- Optimize model performance
- Handle memory and batching
- Scale across users
- Maintain low latency
Even after solving all this, you still need to expose the model as a usable service.
For most teams, this becomes a complex engineering problem. In fact, running the model often becomes harder than building it.
What NVIDIA NIM Does
NIM simplifies this entire process.
It packages AI models into microservices that are:
- Pre-optimized
- Scalable
- Production-ready
You don’t need to:
- Manually optimize models
- Tune GPU performance
- Build serving infrastructure
Instead, you simply call an API.
Behind the scenes, NIM handles:
- Model optimization (via TensorRT-LLM)
- Efficient GPU utilization
- Request batching and scheduling
- Scaling and deployment
This allows developers to focus on building applications rather than managing infrastructure.
Why NIM is a Big Deal
The real value of NIM is not convenience—it’s performance and efficiency.
Each NIM service includes TensorRT-LLM inference engines that are:
- Optimized for specific models
- Tuned for specific GPUs
This means you get high performance out-of-the-box, without manual tuning.
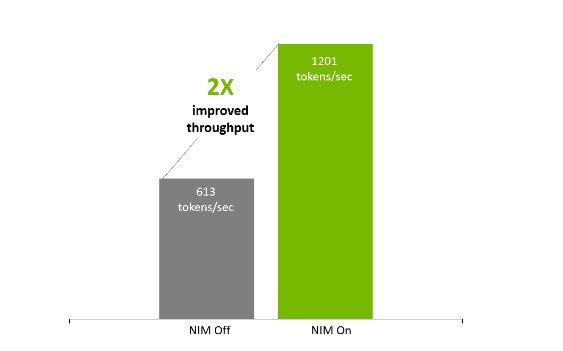
In fact, for models like Llama 3.1 8B on H100 GPUs, NIM can deliver:
Up to 2× throughput compared to leading open-source inference setups
Same model.
Same hardware.
Very different results.
The AI Factory Example (Where It Gets Interesting)
Let’s take this to a real-world scale.
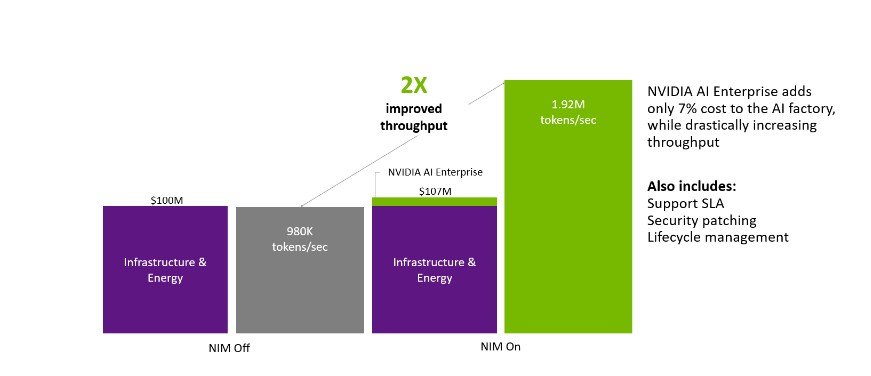
Imagine a modern AI data center (often called an “AI factory”):
- ~1600 H100 GPUs
- ~$100M investment (compute, networking, power, storage)
Running a model like Llama 3.1 out-of-the-box, you might get:
~1 million tokens per second
Now, instead of changing hardware, you simply add:
NVIDIA AI Enterprise (which includes NIM)
What happens?
- Models are automatically optimized
- GPU utilization improves
- Throughput increases
Result:
Up to 2× total throughput
And the cost increase?
Only ~7% for the software layer
Why This Changes Everything
This leads to a powerful outcome:
- Same infrastructure
- Nearly the same cost
- Double the output
In simple terms:
You get 2× AI impact per dollar spent
This is a major shift in thinking.
Most people focus on:
- Better models
- Bigger GPUs
But the real leverage comes from:
Running models smarter, not just bigger
Where NIM Fits in the AI Stack
In a modern AI system:
- Models → provide intelligence
- NIM → makes them usable and efficient
- NeMo → controls workflows and behavior
- Infrastructure → powers everything
Without NIM, models remain difficult to deploy and scale.
With NIM, they become production-ready services.
The Bigger Shift
We are moving from:
❌ Models as static artifacts
✅ Models as optimized, scalable services
Just like cloud computing changed infrastructure, NIM is changing how AI is delivered.
Conclusion
NVIDIA NIM is not just another tool—it is a critical layer that bridges AI models and real-world applications. It simplifies deployment, improves performance, and unlocks efficiency at scale.
The biggest takeaway is this:
- AI performance is not just about the model
- It’s about how efficiently you run it
And in many cases, that difference can mean 2× more output on the same hardware.
Final One-Line Takeaway
NIM doesn’t just run AI models — it maximizes their real-world impact.
